Image to Text
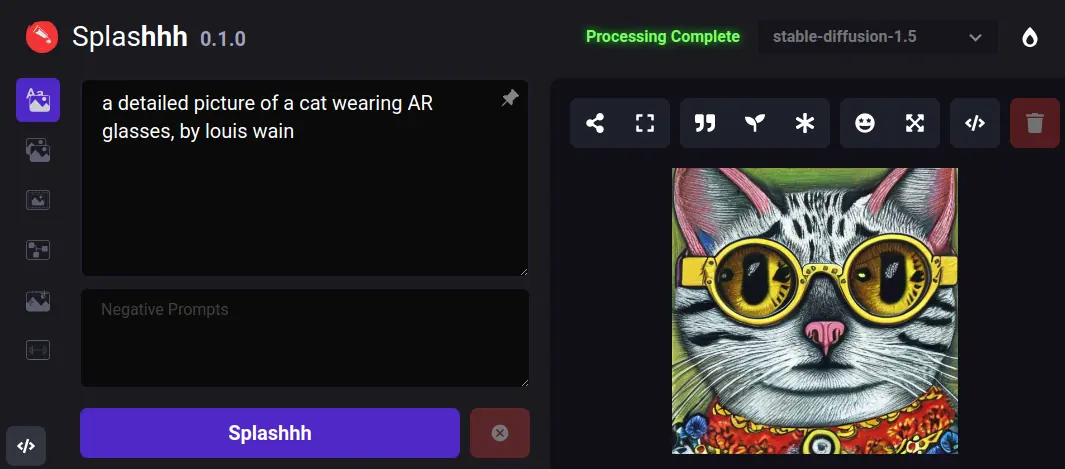
Text to image overview
The text-to-image feature is a functionality within our generative AI platform that enables users to generate images from textual descriptions. With this feature, users can input a written description of an image, and the AI model will generate a corresponding image that closely matches the description. The AI model uses deep learning techniques to understand the semantics of the input text and then generates an image that reflects the meaning and details described in the text. The text-to-image feature has many applications, including digital content creation, e-commerce, and online advertising.
Text to image using AI
The text-to-image feature is based on a generative adversarial network (GAN) architecture, a type of deep learning model consisting of two neural networks - a generator and a discriminator - that work together to produce images. In our implementation, the generator takes a textual description as input, which is first transformed into a latent code using a separate text encoder network. This latent code is then fed into the generator network, which produces an image that matches the input description.
The generator network is trained using supervised and unsupervised learning techniques. During training, the generator is presented with many text-image pairs, and its output is compared against the ground truth image to compute a loss value. The generator is optimized to minimize this loss value, encouraging it to produce pictures as close as possible to the ground truth images.
To ensure that the generated images are of high quality and visually appealing, we also use a discriminator network to evaluate the images produced by the generator. The discriminator is trained to distinguish between real and generated images, and its feedback is used to optimize the generator network further.
Overall, the text-to-image feature is a complex and powerful functionality that requires a sophisticated deep-learning architecture and a large and diverse training dataset. Our platform has been designed to handle these requirements and to provide users with an intuitive and user-friendly interface for generating images from text.
Stable diffusion
The Stable Diffusion model is a type of generative model that is based on a diffusion process. The model is a variation of the well-known Diffusion Probabilistic Model (DPM), which uses a diffusion process to transform a noise vector into an image. The Stable Diffusion model extends this approach by using a stable method, a stochastic process more robust to outliers than the Gaussian process used in the DPM.
The Stable Diffusion model uses a two-step process to generate images. In the first step, the model generates a sequence of noise vectors that are transformed into images using a generator network. This is done by starting with a noise vector drawn from a stable distribution and then applying a series of transformations to increase the complexity and resolution of the image gradually. The generator network consists of multiple convolutional and deconvolutional layers, which extract and refine features in the picture.
The model refines the generated images in the second step using a denoising process. This is done by applying a diffusion process to the generated images, which smoothes out the details and creates a more coherent and visually appealing image. The denoising process is controlled by a diffusion coefficient, which determines the amount of smoothing applied to the image. The diffusion coefficient is learned during training using a maximum likelihood estimation method.
A large dataset of images is required to train the Stable Diffusion model. The model is trained using a maximum likelihood estimation method, which seeks to maximize the likelihood of the training data given the model parameters. The training process involves optimizing the generator and diffusion network parameters and the diffusion coefficient to minimize the difference between the generated images and the ground truth images.
Overall, the Stable Diffusion model is a powerful and flexible generative model well-suited for various image synthesis tasks, including text-to-image generation. Its ability to handle noise and outliers and its flexibility in handling complex and varied datasets make it a popular choice for generative AI applications.